

When an UPDATE Isn’t Really an Update: MySQL vs PostgreSQL (A Deep Dive into the I/O Reality)
If you’ve ever read that “MySQL can update a row in-place without touching indexes” but thought:
“Wait — doesn’t SSD copy it to a new location anyway? Shouldn’t the index change?”
…you’re not alone. This is exactly where physical storage behavior and database engine internals often get mixed up.
so the thing is ……
When you run an UPDATE statement in a database, you’d think it just “changes the data.” But underneath, PostgreSQL and MySQL (InnoDB) handle this operation very differently in ways that matter for write amplification, SSD wear, and query performance.
This difference is one of the key reasons Uber famously migrated from PostgreSQL to MySQL years ago. One of the issues they cited was “update amplification,” which essentially means: one logical change can cause multiple physical writes.
Two Philosophies of Updates
PostreSQL:
PostgreSQL uses Multi-Version Concurrency Control (MVCC) to allow readers and writers to work without blocking each other. Under MVCC, PostgreSQL never overwrites an existing row directly. Instead, when a row is updated or deleted, a new version of that row (called a tuple in PostgreSQL terminology) is written elsewhere in the table, while the old version is simply marked as no longer visible to future transactions. This way, ongoing transactions can continue ‘seeing’ the old version, while new transactions see the updated version enabling consistent snapshots without locking.
A tuple is essentially a single row of data in a table, including both the actual column values plus some hidden fields that PostgreSQL uses to manage transactions and visibility so it can provide high concurrency and isolation.
When you run an UPDATE, PostgreSQL:
- Creates a new version of the tuple with the updated values.
- Marks the old version as dead (no longer visible to future transactions), but leaves it physically in the table for now.
- The old tuple stays there until the VACUUM process reclaims that space.
Because the new tuple version may be stored on a different data page than the old one, a single logical UPDATE can touch multiple pages in storage.
This versioning approach ensures readers see a consistent snapshot of the data as of the moment their transaction started, even if other transactions are updating the same rows at the same time.
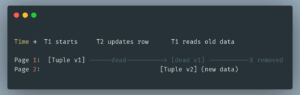
Above is a diagrammatic representation of how PostgresSQL updates a row
MySQL (InnoDB) :
MySQL tries to perform in-place updates whenever it can.
- If the new value still fits inside the free space of the existing page, InnoDB simply modifies the bytes within that page in memory.
- That page is marked dirty, meaning it will eventually be flushed back to disk to the same logical location.
- No new page is allocated, and no old page is deleted in this case, it’s a true overwrite-in-place operation from the database perspective..
But if the updated row grows and no longer fits in its original page:
If the updated row becomes larger and no longer fits in its original page, InnoDB must move it into a new page that has enough free space.The old page isn’t deleted immediately, it simply contains outdated data that will be reused later once the change is made crash-safe via the redo log.After the move, InnoDB automatically updates any secondary indexes so they continue to point to the row using its primary key in the new location.
In short: MySQL tries to update rows in place when possible and only moves them to a new page if they no longer fit. whereas PostgreSQL always creates a new version of the row on update and cleans up the old one later, which leads to more writes but enables its powerful MVCC-based concurrency model.
What Happens in Memory & Disk
Both databases first load the page containing the row into RAM before modifying it. SSDs can’t update bytes in place; they write in blocks.
“The key difference is what happens after the row is updated in RAM”
A page is the smallest I/O unit. Modern SSDs can’t overwrite individual bytes they rewrite entire blocks. so databases always work at the page level.
PostgreSQL
PostgreSQL follows its Multi-Version Concurrency Control (MVCC) model:
- Instead of overwriting the row, it creates a new tuple (a new row version) often on a different page from the original.
- Both the original page and the page with the new tuple are recorded in the Write-Ahead Log (WAL) before any data files are touched.
What is WAL? WAL is a sequential log that captures every change before it’s applied to the main database. This guarantees durability: if PostgreSQL crashes, it can replay the WAL to reconstruct the data.
- With full_page_writes enabled, the first change to a page after a checkpoint will log the entire page to protect against torn writes.
Finally, if the tuple’s physical location changes, PostgreSQL updates all related index entries to point to the new location.
MySQL (InnoDB)
MySQL claims a big advantage by updating rows in-place avoiding extra writes. But on SSDs physical in-place updates aren’t possible so how does MySQL actually achieve this?
When you run an UPDATE statement in MySQL, it may look like the database simply rewrites the row at its original position on disk however, the real process is far more nuanced and involves several layers of indirection and buffering. Let’s walk through how MySQL (specifically the InnoDB engine) updates data and how this interacts with modern SSDs.
Step 1:
- like its mentioned above The 16 KB data page containing the target row is first read into the buffer pool (RAM).
- Then the row is modified inside this in-memory copy.
- The memory page is marked dirty (meaning it has changes that are not yet on disk).
- If the row stays in the same page and its size doesn’t grow beyond the page’s free space, only that one modified page is marked dirty.
Step 2:
Before anything is written back to disk, MySQL appends a small entry to its redo log (also called the WAL — Write Ahead Log). This redo log entry describes the change (e.g., “row X on page Y changed from A to B”).
Step 3:
At some later point (checkpoint), the dirty page in RAM is flushed back to the data file on disk. From the point of view of MySQL and the filesystem, this is an in-place write to the same page number in the tablespace.
But SSDs Don’t Actually Update in Place… Do They?
When MySQL asks the SSD to overwrite a page, the flash chip instead reads the entire large erase-block that contains that page, merges in the new page contents, writes the whole block to a fresh physical location, and marks the old block as invalid for later cleanup because NAND flash cannot modify bytes directly in place.
What MySQL Ensure is :
MySQL ensures the logical page ID stays the same.
logical page ID is InnoDB’s internal page number that identifies the N-th 16 KB page within a tablespace, and this logical page ID is used to compute a file offset (e.g., page 5 → 5 × 16 KB = 80 KB), which the filesystem translates into one or more logical block addresses (LBAs) on the storage device.
When MySQL flushes an updated page, the filesystem tells the SSD to write it to the same Logical Block Address (LBA) which is a virtual address used by the operating system to locate data, but because NAND flash cannot overwrite in place, the SSD’s Flash Translation Layer (FTL) silently maps that LBA to a new physical location, writes the updated data there, and marks the old flash cells as stale, making it appear as though an in-place update occurred even though the underlying hardware actually performed a remap and rewrite.
It’s same logical block address that InnoDB and the OS use to identify the page, though on SSDs the actual physical flash memory cells will be different due to wear leveling and the Flash Translation Layer.
When You Update an Indexed Value in MySQL vs. PostgreSQL
Updating a column that’s part of an index is not just a matter of “changing the value in place.” The database has to maintain index consistency, and because MySQL and PostgreSQL store index pointers differently, the work involved can vary drastically.
PostgreSQL
How indexes store row references:
- Every index entry in PostgreSQL stores a TID (Tuple Identifier), which is a combination of (block/page number, row offset within that page).
- This TID points directly to the tuple’s physical location in the table heap.
What happens when you update an indexed column:
- MVCC kicks in: PostgreSQL never updates a tuple in place. Instead, it creates a brand-new tuple version in the heap.
- New TID assignment: Each row version in the table has a physical location, identified by a TID (a pointer made up of (block, offset)).
- Index maintenance: Because the TID changes, all indexes that involve the updated column need to be taken care of
- Impact: Updating an indexed column is heavier than updating a non-indexed one because of Write I/O, Index bloat (Old index entries remain as dead tuples until VACUUM runs), VACUUM overhead
Updates to indexed columns are always more expensive in PostgreSQL than to non-indexed columns, because a new tuple version always means index pointer changes.
MySQL (InnoDB)
How indexes store row references:
- Primary Key (PK) index: InnoDB uses a clustered index the table data is physically stored inside the B-tree structure of the PK index.
- Secondary indexes: Store the PK value, not the physical location. When MySQL needs to fetch a row from a secondary index, it does a PK lookup using that stored PK value.
What happens when you update an indexed column:
- If the column is part of the Primary Key: Updating it requires physically relocating the entire row in the clustered index tree. As a result, every secondary index that stores this PK value must be updated to point to the new location, making this the most expensive case.
- If the column is part of a secondary index (but not the PK): Only that particular secondary index entry needs to be updated.Since secondary indexes point to the PK value (not a physical location), other indexes remain unaffected, so this is cheaper than a PK update.
- If the column is neither PK nor indexed: MySQL simply updates the row in place inside the clustered index. No index maintenance is required, making this the cheapest type of update.
Cost factor:
- Updating a PK column in MySQL is particularly costly due to the cascading effect on all secondary indexes.
- Updating a secondary indexed column is cheaper than in PostgreSQL because only that index changes, not all indexes containing the PK.
Postgres ends up writing a lot more data when you update an indexed column, causing higher write amplification because it rewrites the whole row and all of its indexes (if multiple columns are indexed). MySQL usually updates only the affected index, so it does much less extra writing.
Why PostgreSQL “Writes More” and Why That’s Actually Smart
If you compare PostgreSQL and MySQL, you’ll notice PostgreSQL often writes more data to disk when a row is updated. At first glance, this looks wasteful. So why do so many companies still choose it for serious systems?
Because PostgreSQL is spending extra disk writes to give you something far more valuable: smoother performance under heavy traffic.
⚡ Fast reads while writes are happening
When PostgreSQL updates data, it doesn’t overwrite the old row, it creates a new version and keeps the previous one too. This means readers can continue to access the old version while writers are busy creating the new version. Result? Readers and writers don’t block each other, so the system stays fast even under heavy load.
🔒 Safer, cleaner transactions (snapshots)
Each transaction in PostgreSQL gets its own snapshot of the database like a frozen picture of what the data looked like when the transaction began. Even if other transactions are changing data at the same time, your transaction won’t see any half-finished updates. That leads to accurate, predictable results without having to use heavy locking.
🧠 Long-running reports don’t slow down live updates
Imagine running a big analytics report that takes several minutes. In some databases, that can block new writes from happening until the report finishes. In PostgreSQL, thanks to row versioning, the report reads old versions of the data, while the live system continues writing newer versions. You get real-time inserts/updates AND smooth reporting at the same time.
🚑 Easier crash recovery & replication
PostgreSQL writes every change into a Write-Ahead Log (WAL) before applying it to the main data. This extra logging makes it easy to:
- Recover after a crash by replaying those logs
- Stream those logs to replicas for real-time standby servers It’s like having a built-in backup recorder that helps keep your data safe and clones perfectly in sync.
👊 Handles write-heavy workloads without locks
When many updates target the same rows, most databases use locks to keep things in order but locks create waiting lines! PostgreSQL avoids this by quietly creating new row versions in the background. Instead of users fighting over the same copy, they each work on their own version, which later gets cleaned up automatically. This keeps high-write workloads smooth and conflict-free.